
- Index
- >Projects
- >Past projects
- >APACOSI
APACOSI Research Project
Deep Learning and Structural Knowledge for Image Analysis
Group : Information, Signal, Image and Life Sciences
Labelling: none
Duration: 36 months (09/01/2019 - 09/01/2022)
Funding: RFI Atlanstic 2020, University of Angers
Staff involved from LARIS: Jean-Baptiste Fasquel, Jérémy Chopin (PhD student)
Project partners: Harold Mouchère (LS2N/IPI), Rozenn Dahyot (Trinity College Dublin, Irelande), Isabelle Bloch (LTCI, Paris)
Abstract and objectives
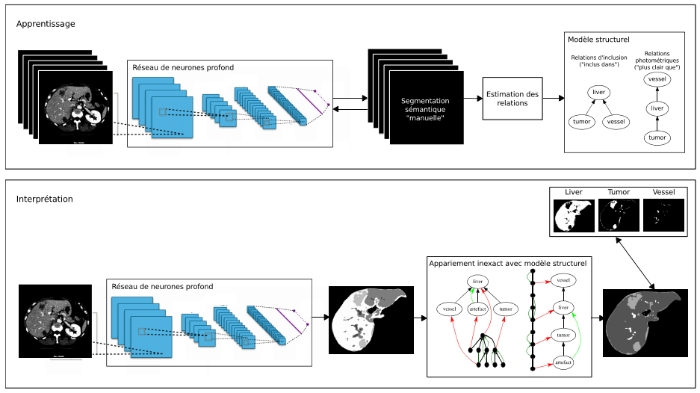
Recent research in image analysis shows the potential of highly supervised learning techniques such as deep learning. The main limitations of this type of approach are the need for a large learning base, which is often difficult to acquire, and the difficulty of training the model with several thousand parameters, even if transfer techniques can accelerate this learning. Before this revolution, ad-hoc approaches required much less data but a lot of expertise to choose the right information to use and the right tools to combine them. Structural analysis approaches are a good example: the image is cut into small entities (related components, super-pixels, regions, objects...) with relations (spatial, photometric...) that constitute a graph allowing the structural analysis of the image.
Such ad-hoc analysis is often time consuming (e.g. matching of large graphs). The challenge we propose to address in this project is to take advantage of both approaches: deep learning with less training data thanks to the use of a priori structural knowledge, to finally produce a structured result. The proposed approach is to rely on qualitative structural a priori knowledge (spatial, photometric relations...), which is simpler to define and formulate (e.g. "to the right of", "included in", "darker than"). This type of supervised approach mimics the human visual system to understand the content of a scene, by working on the observed qualitative relations. We also want to focus on the sequential interpretation of the scene, the way human vision works, where the most salient structures are first identified. We then rely on the a priori known relations as well as on the already identified structures to extract and identify the following ones, according to a strategy to be defined [1] [2]. This type of sequential approach is often used in the case of complex scenes for which a global treatment is not adapted.
The locks to be lifted are :
- How to couple this type of structural approach to highly supervised approaches of the "deep learning" type, while reducing the size of the learning base?
- How, in the case of sequential processing, to learn the best analysis strategy?
Concerning the first lock, the objective is to find how to integrate structural knowledge into neural networks (e.g. deep learning). A first approach will be to dedicate the extraction of basic entities to a deep convolutional network [3], to evaluate if the relations between the entities produced correspond to the a priori relations, for example by relying on graph matching [1] [4]. The benefit of this approach will be studied, in particular its ability to reduce the volume of data required for learning.
Concerning the second lock, the strategy will be to study the coupling of structure information with the use of techniques such as reinforcement learning or recurrent attention models [5] [6]. This type of technique, based on the notion of reward to be maximized, will allow to determine the best analysis sequence [2]. This reward can be evaluated by designing a metric to quantify the adequacy between the obtained result and the a priori structural information, for example by defining distances between relations and taking into account their quality [7].
This work will be evaluated on datasets adapted to the use of structural information, with a focus on medical applications (relationships between anatomical and pathological structures), application areas corresponding to the partners' expertise.
Bibliography
[1] J.-B. Fasquel et N. Delanoue, «An approach for sequential image interpretation using a priori binary perceptual topological and photometric knowledge and k-means based segmentation», Journal of the Optical Society of America A, 2018.
[2] G. Fouquier, J. Atif et I. Bloch, «Sequential model-based segmentation and recognition of image structures driven by visual features and spatial relations», Comp. Vision & Image Understanding, 2012.
[3] G. Roman-Jimenez, C. Viard-Gaudin, A. Granet et H. Mouchère, «Transfer Learning for Structures Spotting in Unlabeled Handwritten Documents using Randomly Generated Documents», International Conference on Pattern Recognition Applications and Methods, 2018.
[4] J.-B. Fasquel et N. Delanoue, «A graph based image interpretation method using a priori qualitative inclusion and photometric relationships», IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018.
[5] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg et D. Hassabis, «Human-level control through deep reinforcement learning», Nature, vol. 2015.
[6] V. Mnih, N. Heess et A. Graves, «Recurrent models of visual attention», In Advances in neural information processing systems, 2014.
[7] I. Bloch et J. Atif, «Defining and computing Hausdorff distances between distributions on the real line and on the circle: link between optimal transport and morphological dilations», Mathematical Morphology: Theory and Applications, 2016.
